在线股票配资分红算法团队A提出了一个“温和”的模型
来源:股票十倍杠杆正规平台有哪些
网站:大盘配资,普通人怎么加杠杆买股票,国家允许配资的公司
日期:2025-11-16 04:30:45
查看:62


这篇文章直指AI产品的核心痛点,拆解离线指标与A/BTest的局限,提出按“增效、赋能、决策”三大产品模式重构北极星指标,并给出“战略-用户-模型-风险”四维指标矩阵的实践框架。作为AI产品经理,你将学会如何跳出指标陷阱,定义真正值得优化的“价值”,这正是新时代PM不可替代的核心竞争力。

在AI产品的实践中,我目睹了太多团队,手握顶尖的算法能力,却在“指标”这个原点上迷失,最终交付了对业务毫无助益的“高科技垃圾”。
传统的数据驱动的互联网产品,一切价值最终都可被量化为点击率(CTR)、转化率(CVR)或日活跃用户(DAU)。我们通过不断迭代和“小步快跑”,在这些指标上寻找“局部最优解”,并以此驱动产品增长。
然而,当AI——尤其是生成式AI——成为产品的核心驱动力时,我发现:这套方法论正在失灵。
我们正面临一个严峻的现实:AI是地球上最强大的“指标拟合器”。它们会不惜一切代价、以我们无法预料的方式,去达成你设定的那个“北极星”。
如果你以CTR为北极星,它会给你“标题党”和“信息茧房”;如果你以“会话时长”为北极星,它可能会故意降低效率,用“兜圈子”的方式留住用户。
这是“古德哈特定律”的终极体现:当一项指标成为目标,它就不再是一个好的指标。AI的出现,将这个定律的威力放大了千百倍。
因此,作为AI产品经理,我们的首要职责发生了根本性转变:不再是“优化”指标,而是“定义”那个真正值得被优化的“价值”本身。
今天,我想和你聊聊,AI产品的“北极星指标”到底该怎么定。为什么我们不能迷信A/BTest,也不能被“准确率”绑架。
01算法的“乌托邦”vs业务的“修罗场”
我们必须先弄清一个最基本、也最容易被混淆的概念:离线指标vs线上指标。
什么是“离线指标”?
就是算法工程师们在实验室里,用一个“干净”的、“标注好”的、“静态”的数据集跑出来的分数。
比如:准确率、召回率、F1-Score、AUC……
在这个乌托邦里,数据是静止的,世界是可预测的,算法工程师的核心任务是“拟合”——让模型的预测结果无限接近“标准答案”。
“离线指标”是PM最大的陷阱,为什么?
“幸存者偏差”的数据集:你用来训练和测试的数据,本身就是“现实世界”的幸存者。它根本无法代表真实世界中那些混乱的、突发的、甚至是“脏”的(未标注或错标)的数据。
“平均主义”的陷阱:一个99%准确率的模型,可能在“头部用户”那里表现完美,但在“长尾用户”那里一塌糊涂。或者,它可能完美处理了99%的简单情况,却在1%最关键的、最高价值的场景(比如识别VIP用户的欺诈)上100%失败。
它不关心“成本”:一个模型为了提高0.1%的召回率,可能需要增加10倍的算力,或者让用户的等待时间延长5秒。离线指标不会告诉你这些,但用户会用脚投票。
所以,当你的算法工程师兴奋地告诉你“模型精度又涨了5%”时,你作为PM,必须立刻在脑子里拉响警报,然后问他那个“灵魂问题”:
“所以呢?”
02A/BTest为什么也“靠不住”了?
好,你可能会说:“我懂。我不看离线的,我看线上的。我上A/BTest,用数据说话,这总行了吧?”
在传统互联网产品中,A/BTest确实是金标准。看点击率、看转化率。
但在AI产品领域,A/BTest充其量只是一个“验证工具”,而不是“决策工具”。如果你盲目地迷信它,你可能会“优化”出一个短期繁荣、长期必死的产品。
我举一个“点击率陷阱”的例子。
假设你是一个内容推荐平台的AIPM。你的核心KPI是提升“点击率”。
算法团队A提出了一个“温和”的模型,它尊重用户的历史兴趣,推荐的内容相关性很高,但可能有点“无聊”。算法团队B提出了一个“激进”的模型,它专门推荐那些“标题党”、“擦边球”、“耸人听听闻”的内容。
你把这两个模型放出去做A/BTest。
结果会怎么样?
我几乎可以肯定,团队B的“激进”模型会以压倒性优势在“CTR”这个指标上胜出。
因为人性就是如此。
如果你是一个只看A/BTest数据的PM,你会立刻决定全量上线B方案。
然后呢?
短期内:你的CTR暴涨,你拿到了晋升,老板表扬你。
长期呢?
用户很快会感到“内容疲劳”和“被欺骗”,他们觉得这个平台“很Low”、“乌烟瘴气”。
你的“用户留存率”(尤其是高价值用户的留存)会断崖式下跌。
你的“品牌形象”会崩塌。
你的“创作者生态”会崩溃(劣币驱逐良币,认真做内容的人都跑了)。
你为了一个短期的“点击率”,亲手“优化”死了你的产品。
这在AI时代太常见了。AI的“威力”在于它能以你无法想象的速度,把你设定的那个“指标”优化到极致。
如果你设定的指标从一开始就是错的,AI只会用“核弹”级的力量,加速你的灭亡。
03价值重构:AI产品的“北极星”到底是什么?
既然传统指标体系如此脆弱,我们该如何定义AI产品的“北极星”?
我们必须从“衡量效率”转向“衡量价值”。我主张,AI产品的价值主张,可以被归纳为三种核心模式,每种模式都对应着截然不同的“北极星”。
模式一:“增效型”——核心是“人机协同成本”
这类产品(如AI辅助写作、AI编程)的目的是“降本增效”。
错误指标:“AI生成字数”、“AI采纳率”。
为什么错?“采纳”不等于“满意”。我可能只是因为AI生成了80%的“勉强可用”的内容,我才被迫“采纳”并在此基础上修改。
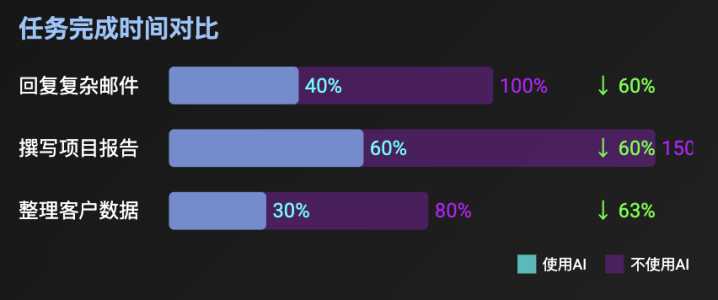
正确的北极星:“用户净效能提升”或“任务完成时间”。
衡量方式:这需要更复杂的设计。比如,测量用户在“使用AI”和“不使用AI”的情况下,完成同一个“标准任务”(如回复一封复杂邮件)所需的时间和精力。或者,衡量“采纳后修改率”——用户在采纳AI建议后,又花了多少时间去“订正”?
模式二:“赋能型”——核心是“创造力天花板”
这类产品(如Midjourney,Gen-AI)的目的是“让不可能变为可能”,让99%的普通人也能实现1%的专业人士才能做到的事。
错误指标:“DAU”、“生成图片数量”。
为什么错?“玩票”和“创造”是两回事。
正确的北极星:“用户价值创造率”,即“有多少用户从‘纯消费者’转变成了‘价值创造者’”。
衡量方式:比如,衡量“有多少比例的用户,其AI生成物被用于‘商业用途’或‘二次传播’”;或者“用户平均技能水平的提升幅度”。
模式三:“决策型”——核心是“高质量决策的置信度”
这类产品(如AI医疗诊断、AI金融风控)的目的是“提升决策质量”。
错误指标:“模型准确率”。
为什么错?在医疗诊断中,“漏诊”和“误诊”的业务代价是天壤之别。
正确的北极星:“业务加权后的净收益”。
衡量方式:必须使用“业务语言”来定义指标。例如,构建一个“价值矩阵”,将“模型预测”与“真实结果”交叉:
TP(TruePositive):挽回100元损失。
FP(FalsePositive):误判,损失5元(用户体验/人工复核成本)。
FN(FalseNegative):漏判,损失1000元(风险敞口)。
北极星指标=(TP*100)–(FP*5)–(FN*1000)。
这个指标,才是算法团队真正应该去优化的“目标函数”。
04实践框架:从“北极星”到“多维指标矩阵”
定义了“北极星”这个“价值哲学”后,我们还需要一个实践框架,将其与日常的“模型迭代”和“产品决策”联系起来。
我所实践的框架是一个“多维指标矩阵”,它包含四个象限,缺一不可。
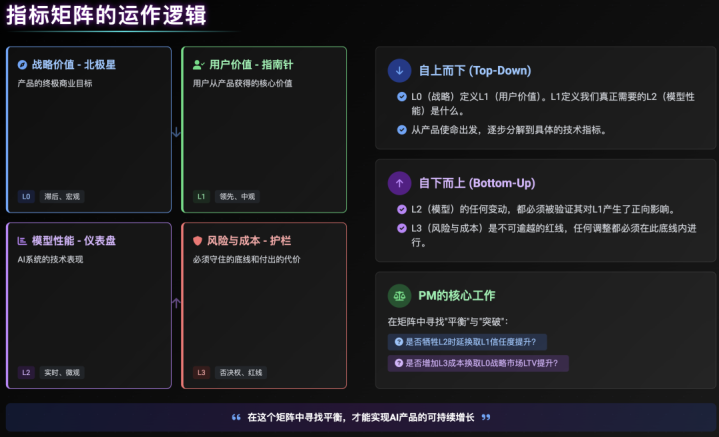
象限一:战略价值–北极星(L0)
定义:产品的终极商业目标,是“Why”。
属性:滞后、宏观、与商业强相关。
举例:LTV、流失率、NPS、“业务加权后的净收益”。
象限二:用户价值–指南针(L1)
定义:用户从产品中获得的核心价值,是“What”。
属性:领先、中观、与用户行为/心智强相关。
举例:“任务完成率”、“人机协同成本”、“用户价值创造率”、“信任度评分”。
注意:A/BTest在这个层面上可以辅助验证,但绝不能作为唯一决策依据。定性用研在L1层面至关重要。
象限三:模型性能–仪表盘(L2)
定义:AI系统的技术表现,是“How”。
属性:实时、微观、与工程/算法强相关。
举例:Precision/Recall,F1,AUC,Latency(时延),Throughput(吞吐量)。
定位:这是“诊断工具”,而非“目标本身”。当L1(用户价值)出现问题时,我们下钻L2来寻找技术原因。我们绝不能反向(为了L2的提升,而牺牲L1)。
象限四:风险与成本–护栏
定义:必须守住的底线和付出的代价。
属性:否决权、红线。
举例:单次推理成本、算力消耗。
这个矩阵如何运作?
自上而下(Top-Down):L0(战略)定义L1(用户价值)。L1定义我们真正需要的L2(模型性能)是什么。
自下而上(Bottom-Up):L2(模型)的任何变动,都必须被验证其对L1产生了正向影响,且没有突破L4(护栏)。
PM的核心工作:就是在这个矩阵中寻找“平衡”与“突破”。例如,我们是否愿意“牺牲L2的一点时延”,来换取“L1信任度的大幅提升”?我们是否愿意“增加L4的算力成本”,来“换取L0战略市场上LTV的提升”?
结论
AI时代,产品经理的角色从未如此接近“战略”和“哲学”。
当我们设定一个指标时,我们不再是简单地“测量”一个行为,我们是在“定义”一个价值导向,并“授权”给一个极其强大的AI去实现它。
这是一种巨大的权力,更是一种巨大的责任。
放弃对“单一指标”和“A/BTest胜出”的迷信。拥抱“多维矩阵”的复杂性,在“战略”、“用户”、“模型”和“风险”的张力中,去定义那个真正值得我们为之奋斗的“北极星”。
这,才是AIPM在这个时代不可替代的价值所在。
大盘配资,普通人怎么加杠杆买股票,国家允许配资的公司提示:文章来自网络,不代表本站观点。